Функция TEXTAFTER в Excel возвращает текст, который находится после заданной подстроки или разделителя. В случаях, когда в тексте встречается несколько разделителей, функцию может возвращать текст после n-го появления разделителя.
Что делает функция TEXTAFTER в Excel
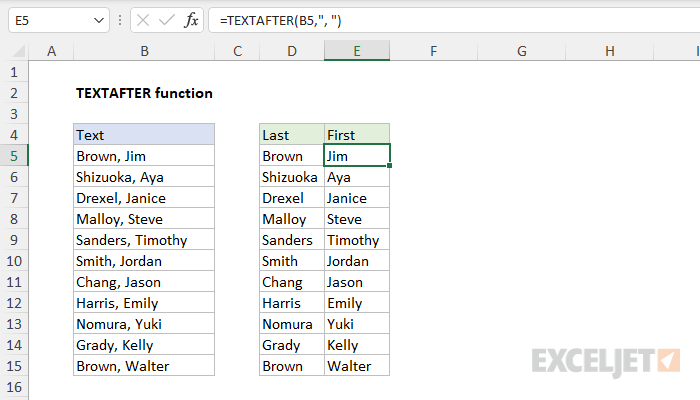
Функция TEXTAFTER в Excel возвращает текст после разделителя.
Возвращаемое значение
Извлеченный текст.
Аргументы
- text — текстовая строка, из которой нужно извлечь.
- delimiter — Символ(ы), которые ограничивают текст.
- instance_num — [необязательно] Экземпляр разделителя в тексте. По умолчанию — 1.
- match_mode — [необязательный] Учет регистра. 0 = включено, 1 = отключено. По умолчанию — 0.
- match_end — [необязательно] Считать конец текста разделителем. 0 = отключено, 1 = включено. По умолчанию — 0.
- if_not_found — [необязательно] Значение, возвращаемое, если совпадение не найдено. #Н/Д — значение по умолчанию.
Синтаксис
=TEXTAFTER(text, delimiter, [instance_num], [match_mode], [match_end], [if_not_found])
Примечания по использованию
Функция TEXTAFTER извлекает текст, который находится после заданного разделителя. Если в тексте присутствует несколько разделителей, функция может возвращать текст, который находится после n-го экземпляра разделителя. В отличие от функции TEXTSPLIT, выходные данные представляют собой одно значение.
TEXTAFTER принимает шесть аргументов; необходимы только первые два. Первый аргумент text — это текстовая строка для обработки. Второй аргумент, delimiter, — это подстрока, которая будет использоваться в качестве разделителя при извлечении текста. Требуются как текст, так и разделитель.
Третий аргумент, instance_num, представляет собой целое число, которое представляет n-й экземпляр разделителя в тексте (т. е. чтобы извлечь текст после второго экземпляра, используйте 2 для instance_num). Если параметр не указан, значение instance_num по умолчанию равно 1.
Четвертый аргумент — match_mode, который контролирует чувствительность к регистру при поиске разделителя. По умолчанию TEXTAFTER чувствителен к регистру, а match_mode равен нулю (0). Поставьте 1, чтобы отключить чувствительность к регистру.
Пятый аргумент match_end позволяет TEXTAFTER обрабатывать конец текстовой строки как разделитель. По умолчанию match_end равен 0, а функция не будет использовать конец текстовой строки в качестве разделителя. Установите для match_end значение 1, чтобы TEXTAFTER использовал конец текстовой строки в качестве разделителя.
Последний аргумент — if_not_found, пользовательское значение, которое возвращается, когда TEXTAFTER не соответствует никакому тексту. По умолчанию TEXTAFTER вернет #N/A. Примеры см. ниже.
Используйте TEXTAFTER для извлечения текста после разделителя, TEXTBEFORE для извлечения текста перед разделителем и TEXTSPLIT для извлечения всего текста, разделенного разделителями.
Основное использование
Чтобы извлечь текст, который появляется после определенного символа или подстроки, укажите текст и символы, которые будут использоваться в качестве разделителя, в двойных кавычках («»). Например, чтобы извлечь имя из «Джонс, Боб», укажите в качестве разделителя запятую в двойных кавычках («,») :
=TEXTAFTER("Jones,Bob",",") // возвращает "Bob"
В качестве разделителя можно использовать более одного символа. Например, чтобы извлечь второй размер из текстовой строки «12 футов x 20 футов», используйте «x» в качестве разделителя:
=TEXTAFTER("12 ft x 20 ft"," x ") // возвращает "20 ft"
Обратите внимание, что мы включаем пробел до и после x, поскольку все три символа служат разделителями.
Текст после разделителя n
Чтобы извлечь текст после n-го появления разделителя, укажите значение для instance_num. Приведенные ниже формулы извлекают текст после первого и второго появления символа дефиса («-»):
=TEXTAFTER("ABX-112-Red-Y","-",1) // возвращает "112-Red-Y"
=TEXTAFTER("ABX-112-Red-Y","-",2 // возвращает "Red-Y"
TEXTAFTER вернет #N/A, если указанный экземпляр не найден.
Текст после разделителя -n
TEXTAFTER поддерживает отрицательные значения для instance_num, что позволяет возвращать текст после последнего появления разделителя, например:
=TEXTAFTER("ABX-112-Red-Y","-",-1) // возвращает "Y"
=TEXTAFTER("ABX-112-Red-Y","-",-2) // возвращает "Red-Y"
Если instance_num выходит за пределы диапазона, TEXTAFTER возвращает ошибку #N/A.
Сопоставить конец текста
Обычно TEXTAFTER не рассматривает конец текстовой строки как разделитель. Например, в приведенной ниже формуле запрашивается текст после разделителя 3, считая от конца (обратите внимание на минус 3):
=TEXTAFTER("ABX-123-Red-XYZ","-",-3) // возвращает "123-Red-XYZ"
И эта формула возвращает #N/A, поскольку нет четвертого разделителя с конца:
=TEXTAFTER("ABX-123-Red-XYZ","-",-4) // возвращает #N/A
Если мы включим match_end, указав 1, формула будет вести себя так, как будто разделитель существует перед «ABX», который является «концом» строки при обратном счете.
=TEXTAFTER("ABX-123-Red-XYZ","-",-4,,1) // возвращает всю строку целиком
Будьте осторожны в ситуациях, когда разделитель не может быть найден, а функция match_end включена. Если параметр match_end включен и номер экземпляра равен 1, TEXTAFTER вернет пустую строку («»), если разделитель не найден. Если параметр match_end включен и номер экземпляра равен -1, TEXTAFTER вернет всю строку, если разделитель не найден.
Несколько разделителей
Чтобы одновременно предоставить в TEXTAFTER несколько разделителей, вы можете использовать константу массива, например {«x»,»y»}, где x и y представляют разные разделители. Одним из применений этой функции является обработка противоречивых разделителей в исходном тексте. Например, на листе ниже разделитель отображается в виде запятой с пробелом («,») и запятой без пробела («,»). Если указать константу массива {«, «,»,»} в качестве разделителя, оба варианта будут обработаны правильно:
=TEXTAFTER(B4,{", ",","})

Чувствительность к регистру
По умолчанию TEXTAFTER при поиске разделителя учитывает регистр. Такое поведение контролируется аргументом match_mode — логическим значением, которое включает и отключает чувствительность к регистру. По умолчанию match_mode имеет значение FALSE.
В приведенном ниже примере разделитель отображается как «x» и «X» (верхний и нижний регистр «x»). Формула в D4 устанавливает match_mode в значение TRUE, что отключает чувствительность к регистру и позволяет TEXTAFTER соответствовать обеим версиям разделителя:
=TEXTAFTER(B4," x ",,TRUE) // отключить чувствительность к регистру

Примечание: вы можете использовать 1 и 0 вместо TRUE и FALSE для аргумента match_mode.
Примечания
- TEXTAFTER по умолчанию чувствителен к регистру.
- Вернет #N/A! ошибка, если разделитель не найден.
- Вернет #VALUE! ошибка, если text пуст.
- Вернет #N/A, если instance_num выходит за пределы диапазона.